
Calculating the average of a variable or column is a common operation that you can carry out in many ways. Besides the (normal) average, you might also need the weighted average. But, how do you calculate the weighted average (per group) in SAS?
In SAS, you can calculate the weighted average with PROC SQL, PROC MEAN, PROC UNIVARIATE, or with a Data Step. In this article, we discuss these 4 methods. Additionally, we show how to calculate the weighted average per group.
Contents
Calculate the Weighted Average in SAS
In the examples in this section, we use a dataset that contains the result of an exam of 4 questions (A, B, C, and D). Each question has a weight (wt) and a score (score). We want to calculate the weighted average of the score variable (also weighted mean).
/* Sample Data */ data work.my_data; input question $ wt score; datalines; A 10 70 B 30 65 C 50 85 D 10 80 ; run;
Do you know? How to calculate the Moving Average
Method 1: PROC SQL
The first method to calculate the weighted average in SAS is with PROC SQL. The code is straightforward and easy to remember. You simply write out the formula of the weighted average. That is, you take the sum of the weights multiplied by the scores, and you divide this by the sum of the weights.
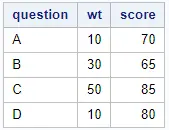
proc sql; create table work.weighted_average as select sum(wt * score) / sum(wt) as weighted_average from work.my_data; quit;

You can decide to include the CREATE TABLE statement, depending on your needs. If you omit this statement, SAS will only create a report. Otherwise, it will create a SAS table with the weighted average.
Method 2: PROC MEANS
The second method to calculate the weighted average is with PROC MEANS.
PROC MEANS is a common and powerful SAS procedure to quickly analyze numerical data. By default, it shows you the number of observations, the mean, the standard deviation, the minimum, and the maximum for each numeric column. However, with some modifications, you can use PROC MEANS also to calculate the weighted mean.
In the first line of code, you call the PROC MEANS procedure and define the input data (work.my_data). You also specify that you want to calculate the sum, the sum of weights, and the mean.
In the second line, you use the weight keyword to let SAS know to calculate the weighted mean instead of the normal mean.
With the var keyword, you specify for which variable you want to calculate the sum and weighted mean.
Finally, with the output keyword, you create an output dataset (work.weighted_average). After the name of the output dataset, you specify which statistics to include and how to call them.
proc means data=work.my_data sum sumwgt mean; weight wt; var score; output out=work.weighted_average mean=weighted_average; run;

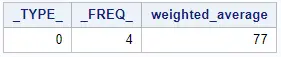
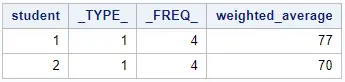
By default, SAS includes the _TYPE_ and _FREQ_ columns in the output dataset.
Method 3: PROC UNIVARIATE
The third method to calculate the weighted average in SAS is with PROC UNIVARIATE.
PROC UNIVARIATE is a SAS procedure to examine the distribution of your data, including the assessment of normality and the detection of outliers. By default, PROC UNIVARIATE shows more statistical information than PROC MEANS.
The code to calculate the weighted mean with PROC UNIVARIATE is very simple. With the weight keyword, you specify that all calculated statistics must be weighted. You use the var keyword to let SAS know which variable to analyze.
If you want an output dataset, you need the output keyword followed by the desired name of the output dataset and the statistics/columns.
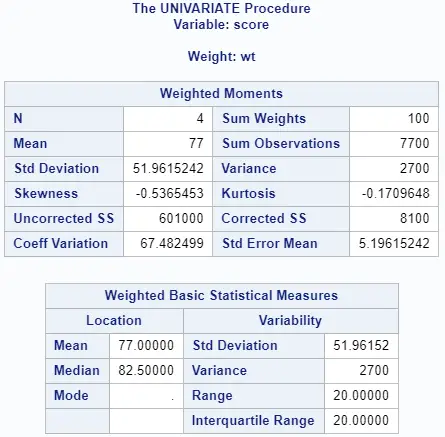
proc univariate data=work.my_data; weight wt; var score; output out=work.weighted_average mean=weighted_average; run;

Method 4: Data Step
The fourth method to calculate the weighted average is with a SAS Data Step.
This method is the most complicated and requires the most code. However, since SAS processes data row-by-row, you can use this method to calculate a rolling weighted average.
As mentioned, SAS processes data row-by-row and “forgets” everything about the previous row when it starts processing a new row. However, to calculate the (rolling) weighted average of a given row, SAS needs to know the sum of weights and the sum of weights times the score of the preceding rows. For this reason, we use the RETAIN statement. With the RETAIN statement SAS “remembers” information of the previous row.
In the example below, sum_wt contains the sum of weights of all previous rows including the current row. The column sum_wt_x_score shows the sum of the weights multiplied by the scores up to a given row. Finally, rolling_weighted_average contains the rolling average until a specific row. The last rolling weighted average is the weighted average of the complete dataset.
data work.rolling_weighted_average; set work.my_data; retain sum_wt sum_wt_x_score; sum_wt = sum(sum_wt, wt); sum_wt_x_score = sum(sum_wt_x_score, score * wt); rolling_weighted_average = sum_wt_x_score / sum_wt; run;
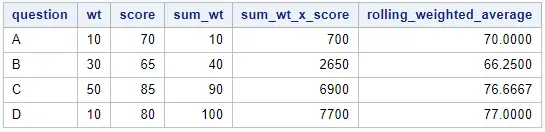
If you are only interested in the (final) weighted average of the dataset (77.0), then you need an extra Data Step. With the Data Step below, we only select the last row and rename the column rolling_weighted_average to weighted average.
data work.weighted_average (keep=weighted_average); set work.rolling_weighted_average (rename=(rolling_weighted_average = weighted_average)) end=eof; if eof then output; run;

Check the following articles to better understand the code above:
- Select variables with the KEEP option.
- Rename variables with the RENAME option.
- Select the last observation with the EOF option.
Calculate the Weighted Average per Group in SAS
In this section, we discuss 4 methods on how to calculate the weighted average per group in SAS.
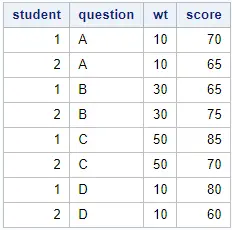
For the examples in this section, we use a dataset with the test scores of 2 students. Each student obtained a score for 4 different questions, each with a different weight. We want to know the weighted average score per student.
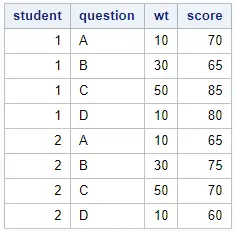
data work.my_data; input student question $ wt score; datalines; 1 A 10 70 2 A 10 65 1 B 30 65 2 B 30 75 1 C 50 85 2 C 50 70 1 D 10 80 2 D 10 60 ; run;
Method 1: PROC SQL
The first method to calculate the weighted average per group is with PROC SQL.
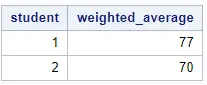
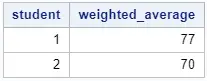
This method is the easiest method, especially if you already know how to program in SQL. We use the GROUP BY statement to calculate the weighted average per student.
proc sql; create table work.weighted_average as select student, sum(wt * score) / sum(wt) as weighted_average from work.my_data group by student; quit;
Method 2: PROC MEANS
The second method to calculate the weighted average per group is with PROC MEANS.
In the SAS code below, we use the data= option to define the input dataset. With the sum, sumwgt, and mean we instruct SAS which statistics to calculate.
The second line of the code uses the class keyword to calculate the statistics (e.g., the weighted mean) separately for each student.
We use the weight keyword to let SAS know to calculate the weighted mean of the score variable (var keyword).
Finally, you can use the output keyword to create an output dataset with the results. After the name of the output dataset (work.weighted_average), you specify which statistics need to be included and their column name.
proc means data=work.my_data sum sumwgt mean nway; class student; weight wt; var score; output out=work.weighted_average mean=weighted_average; run;
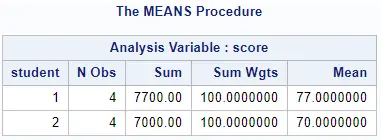
As you can see, the output dataset of PROC MEANS contains, by default, two extra columns, namely _TYPE_ and _FREQ_.
Method 3: PROC UNIVARIATE
The third method to calculate the weighted mean in SAS per group is with PROC UNIVARIATE.
PROC UNIVARIATE is mainly used to examine the distribution of a variable. However, you can also use it to calculate other statistics, such as the weighted mean.
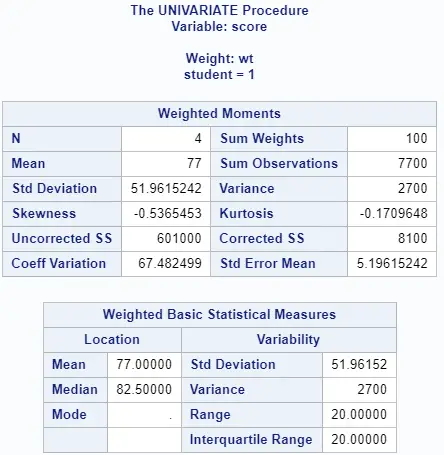
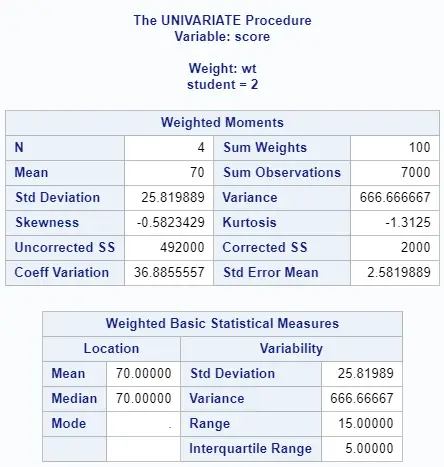
You use the class keyword to calculate the statistics separately for each group (i.e., student). With the var keyword, you specify which variable to examine. To get weighted results, you use the weight keyword.
If you need an output table with the weighted average, you use the output keyword followed by the desired table name and the required statistics (and the column name).
proc univariate data=work.my_data; class student; weight wt; var score; output out=work.weighted_average mean=weighted_average; run;
Method 4: Data Step
The fourth and final method to calculate the weighted average per group is with a SAS Data Step.
The first step to calculate the weighted average is to order the dataset by the student column.
proc sort data=work.my_data out=work.my_data_srt; by student question; run;
Because SAS processes data row-by-row, it isn’t possible to calculate the weighted average (per group) with one simple step. In fact, the code below calculates a rolling weighted average per student.
data work.rolling_weighted_average; set work.my_data_srt; by student; retain sum_wt sum_wt_x_score; if first.student then do; sum_wt = wt ; sum_wt_x_score = score * wt; rolling_weighted_average = sum_wt_x_score / sum_wt; end; else do; sum_wt = sum(sum_wt, wt); sum_wt_x_score = sum(sum_wt_x_score, score * wt); rolling_weighted_average = sum_wt_x_score / sum_wt; end; run;
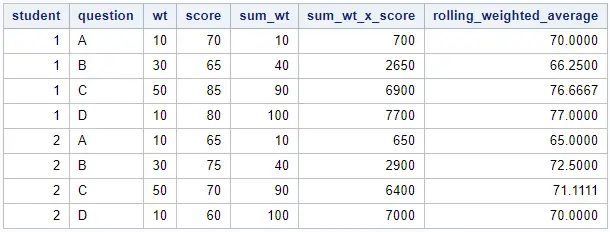
As the table above shows, SAS has calculated a rolling weighted average per student. However, we are only interested in the last row per student. To select the last row per student and only the columns we are interested in, we use a combination of the KEEP option, the RENAME option, and the last keyword.
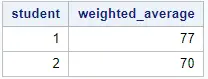
data work.weighted_average (keep=student weighted_average); set work.rolling_weighted_average (rename=(rolling_weighted_average = weighted_average)); by student; if last.student then output; run;


2 thoughts on “4 Ways to Calculate the Weighted Average (by Group) in SAS”
Comments are closed.