If you work with data, sooner or later, you will have to deal with duplicates in your data set. For example, an imported Excel file might contain identical rows or a SQL join results in a data set with similar observations. In this article, we discuss 3 easy ways to find and remove duplicates in SAS.
First, we discuss how to remove duplicates with a SQL procedure. Next, we use the SAS SORT procedure to remove completely identical rows. We also show how to remain the first unique observation given a (list of) variable(s). Finally, we discuss a method on how to store the duplicate rows in a separate data set for further investigation.
Contents
Remove Duplicates in SAS
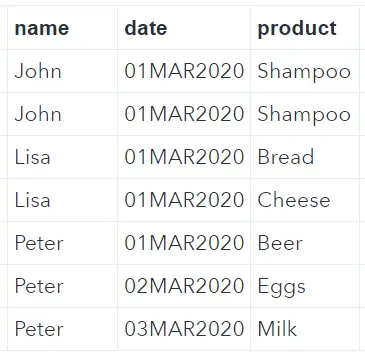
Throughout this article, we use the data set below to show how to find and remove duplicates in SAS. We call the data set work.sales and it contains the name of the buyer, the date of the purchase, and the name of the product bought.
Remove Duplicates with PROC SQL
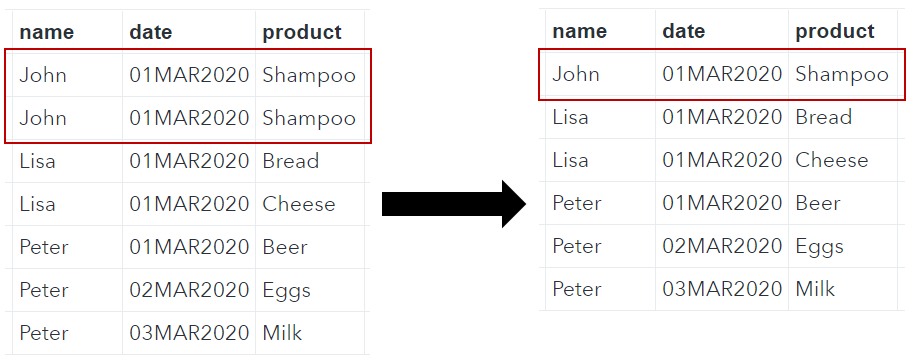
The SAS data set above contains 2 identical rows, namely John – 01MAR2020 – Shampoo. With PROC SQL you can remove duplicate rows intuitively and easily. Within the SELECT clause, you use the DISTINCT keyword to account for duplicate rows. Use the asterisk (*) to select all the columns.
proc sql; select distinct * from work.sales; quit;

Remove Duplicates with PROC SORT
In SAS, you can not only use the PROC SORT procedure to order a data set, but also to remove duplicate observations. To do so you add the keyword NODUPKEY to the sort clause. Depending on which duplicates you want to remove, you need to modify the BY statement. Below we show how.
Exact Duplicates
To remove identical rows from a SAS dataset with the PROC SORT procedure, you use the NODUPKEY keyword and the BY _ALL_ statement. The result of the code below is identical to the PROC SQL procedure discussed above. Here, the NODUPKEY keyword and the BY _ALL_ statement are the equivalent to the DISTINCT keyword and the asterisks in the SELECT clause of the SQL procedure.
proc sort data=work.sales nodupkey; by _all_; run;

Semi Duplicates
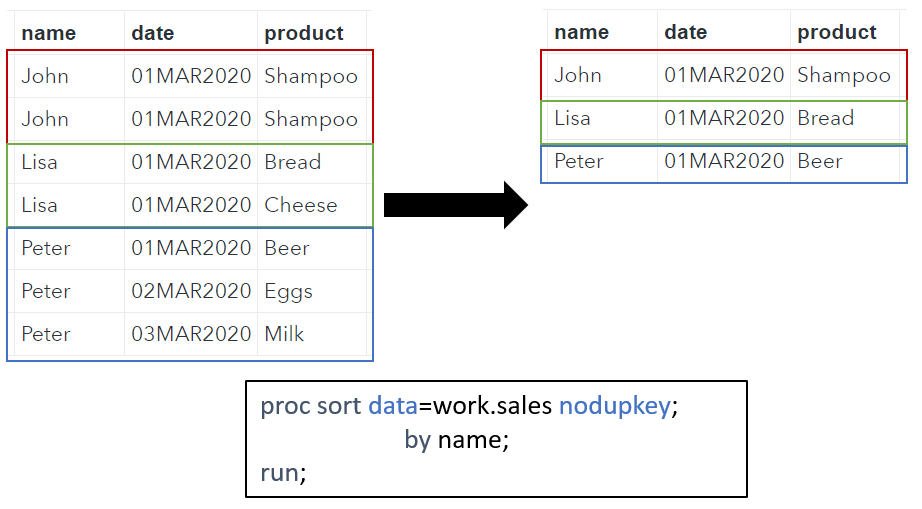
Note that besides two identical observations in the example data set (John – 01MAR2020 – Shampoo), the example data set also contains two persons that made a purchases on the same day, i.e., John and Lisa on the 1st of March. In some situations, you might only be interested in the days when a customer made a purchase. To do so we use only the name and date variable in the BY statement in combination with the NODUPKEY keyword.
proc sort data=work.sales nodupkey; by name date; run;

Note that, by default, SAS maintains all original variables in the output data set. To prevent this, and only maintain the name and date variable, you add out=work.sales_out (keep=(name date)) to the SORT clause.
You can use the same trick if you are only interested in the buyers’ name by reducing the BY statement to BY name.
proc sort data=work.sales nodupkey; by name; run;
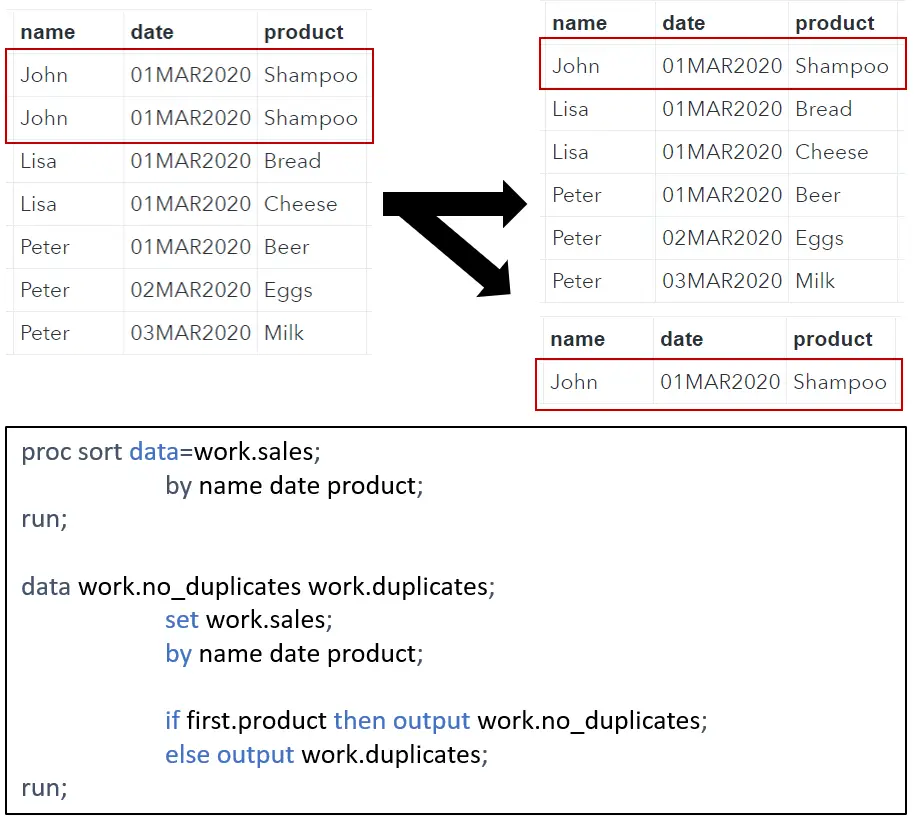
Find Duplicates in SAS
Besides removing duplicate observations, it is sometimes necessary to know which observations are duplicated in the original data set. Although you can use PRC SQL and PROC SORT to remove duplicates, the easiest way to find and store duplicates in a separate data set is with PROC SORT. Below we how.
First, we order the original data set by all variables. However, in contrary to the previous examples, we don’t use the NODUPKEY keyword. Then, we create a data step with two output data set. One with unique observations and one with the duplicate observations. Finally, we use the first keyword to move the first unique observation of the data set to the output data set without duplicates. If the next observation is identical to the previous observations, then this observation is moved to the output data set with duplicates. See the SAS code below.
proc sort data=work.sales; by _all_; run; data work.no_duplicates work.duplicates; set work.sales; by _all_; if first.product then output work.no_duplicates; else output work.duplicates; run;