
If you run experiments or want to analyze a huge dataset, you might need sample datasets. In this article, we discuss 3 easy ways to create a random sample in SAS.
In SAS, you could create random samples with PROC SQL or with a SAS DATA Step. However, the best way to sample data is with PROC SURVEYSELECT. This procedure is easy to understand and can generate a variety of sample types. For example, simple random samples stratified random samples or random samples with replacement.
We discuss these three methods and provide many examples.
Contents
Example Data
In this article, we’ll use the BWEIGHT dataset from the SASHELP library to demonstrate how to create random samples in SAS.
The BWEIGHT dataset provides data of 50.000 babies born in 1997. Amongst others, it contains the weight of the baby and its gender.
The goal is to create a sample of 5.000 (i.e., 10%) observations. We will use the Boy column to generate stratified samples. That is to say, samples of different groups.
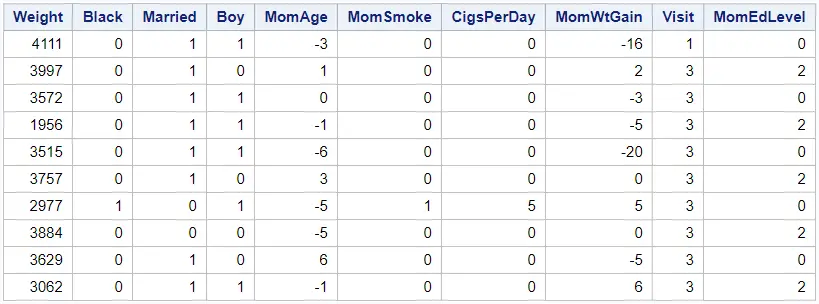
Below, we show the first 10 rows of the BWEIGHT dataset.
proc print data=sashelp.bweight (obs=10) noobs; run;
Do you know? How to Select the First or Last 10 Rows of a Dataset
1. Create a Random Sample in SAS with PROC SQL
The first method to create a random sample in SAS is with the PROC SQL procedure.
This method is easy to understand, especially if you have experience with SQL. However, this method has its limitations. For example, you can neither generate samples per group nor can you sample with replacement.
Still, we will demonstrate how to generate a random sample with PROC SQL. We discuss two types of random samples:
- Random samples with a fixed number of observations
- Random samples with a fixed percentage of observations
Generate a Random Sample Based on a Fixed Number of Observations
In SAS, PROC SQL provides an easy, two-step method to generate a simple random sample with a fixed number of observations. Firstly, you order the dataset randomly with the ORDER BY statement and the RANUNI function. Secondly, you use the OUTOBS=-option to select only the first N observations of the ordered dataset.
The RANUNI function generates a number between 0 and 1 from the uniform distribution. In combination with the ORDER BY statement, you can use the RANUNI function to order a dataset randomly (in ascending order).
Once you have ordered the dataset, you can use the OUTOBS=-option to select just the first N observations. So, if you want a sample of 5000 observations, you use OUTOBS=5000.
In the example below, we create a random sample of 5000 observations from the BWEIGHT dataset.
proc sql outobs=5000; create table work.sample_5000_obs as select * from sashelp.bweight order by ranuni(1234); quit;
Note that SAS writes a warning to the log if you use the OUTOBS=-option and the number of selected observations is less than the total number of observations. In contrast, SAS doesn’t write a warning to the log if you try to select more than the total number of observations.
Generate a Random Sample Based on a Fixed Percentage of Observations
Instead of a sample with a fixed number of observations, you can also sample a fixed percentage of the dataset.
You create a random sample in SAS with a fixed percentage of observations with PROC SQL. Firstly, you assign each observation a random number between 0 and 1 from the uniform distribution. Secondly, you use the WHERE statement to select only those observations with a random number less than the desired percentage.
With the RANUNI function, you can generate numbers between 0 and 1. Since all numbers have the same probability to be generated, you can use the WHERE statement to create a sample of a fixed percentage of observations.
In the example below, we generate a random sample with 10% of the observations of the BWEIGHT dataset.
proc sql; create table work.sample_10_pct as select * from sashelp.bweight where ranuni(1234) lt 0.1; quit;
Note that the generated sample might have slightly more (or fewer) observations than the desired sample size. This is because the RANUNI function returns random numbers.
2. Create a Random Sample in SAS with PROC SURVEYSELECT
The second method to generate a random sample in SAS is with PROC SURVEYSELECT.
The PROC SURVEYSELECT is a powerful procedure that you can use to generate a variety of random samples. For example, simple random samples, stratified samples, or samples with replacement.
Generate a Simple Random Sample
The most straightforward random sample is the Simple Random Sample. This sampling technique randomly selects observations from a dataset without replacement. The sample size is a fixed number of observations or a fixed percentage of observations.
You generate a simple random sample in SAS with PROC SURVEYSELECT by defining at least 3 parameters:
- DATA=-option: With the DATA=-option, you define the dataset from which you want to generate a sample.
- OUT=-option: With the OUT=-option, you define the dataset that will contain the simple random sample.
- SAMPSIZE=-option or SAMPRATE=-option: With the SAMPSIZE=-option or SAMPRATE=-option, you can specify the size of the sample. You use SAMPSIZE and SAMPRATE to define a fixed number of observations or a fixed percentage of observations, respectively.
Simple Random Sample with a Fixed Number of Observations
Below we show how to use PROC SURVEYSELECT to generate a simple random sample of 5.000 observations.
proc surveyselect data=sashelp.bweight out=work.sample_5000_obs seed=1234 sampsize=5000; run;
Note that the SAMPSIZE=-option can’t be negative, nor bigger than the total number of observations in the input dataset. In both cases, SAS generates an error and stops executing the remaining code.
Simple Random Sample with a Fixed Percentage of Observations
The SAS code below demonstrates how to use the SAMPRATE=-option and generate a simple random sample of 10%.
proc surveyselect data=sashelp.bweight out=work.sample_10_pct seed=1234 samprate=0.1; run;
We recommend using sample rates between 0 and 1.
Generate a Random Sample by Group (Stratified Sampling)
Another frequently used sampling technique is Stratified Sampling (or sampling by group). Stratified sampling divides a dataset into two or more groups and generates samples per group.
Creating a stratified sample in SAS is a two-step process. Firstly, you need to sort your dataset based on the variables that define your groups. Secondly, you use the PROC SURVEYSELECT procedure to carry out the sampling. You need to define the following four parameters:
- DATA=-option: With the DATA=-option, you define the ordered dataset from which you want to generate a sample.
- OUT=-option: With the OUT=-option, you define the dataset that will contain the simple random sample.
- SAMPSIZE=-option or SAMPRATE=-option: With the SAMPSIZE=-option or SAMPRATE=-option, you specify the sample size.
- STRATA statement: With the STRATA statement, you specify the variables that define your groups. With the ALLOC=-option you specify how to allocate the sample size among the groups.
In the example below, we generate a stratified sample from the BWEIGHT dataset based on the BOY column. We demonstrate how to use both the SAMPSIZE=-option, as well as the SAMPRATE=-option.
We allocate our sample size among the groups using the ALLOC=prop option. In this case, SAS allocates the sample in proportion to the group size. For more allocation types, see this article.
proc sort data=sashelp.bweight out = work.bweight_sorted; by boy; run; proc surveyselect data=work.bweight_sorted out=work.sample_10_pct_by_group seed=1234 samprate=0.1; strata boy / alloc=prop; run; proc surveyselect data=work.bweight_sorted out=work.sample_5000_obs_by_group seed=1234 sampsize=5000; strata boy / alloc=prop; run;
In the example above, we used one variable to specify the groups in our stratified sample. However, you can use more variables to make your groups more granular.
Generate a Random Sample with Replacement
Although less used, you can also generate a random sample with Replacement with PROC SURVEYSELECT. Sampling with replacement means that a specific observation can be selected more than once.
To generate a random sample with replacement in SAS you need to specify the following parameters:
- DATA=-option: With the DATA=-option, you define the dataset from which you want to generate a sample with replacement.
- OUT=-option: With the OUT=-option, you define the dataset that will contain the simple random sample.
- SAMPSIZE=-option or SAMPRATE=-option: With the SAMPSIZE=-option or SAMPRATE=-option, you specify the sample size.
- METHOD=-option: With the METHOD=-option set to URS, you can create a random sample with replacement.
You can use the METHOD=-option also to generate stratified samples with replacement.
In the example below, we demonstrate how to generate a sample with replacement using both the SAMPSIZE=-option and the SAMPRATE=-option.
To demonstrate that our sample contains observations that occur more than once, we create a new dataset with distinct rows. We use the standard SAS macro variable sqlobs to print the number of distinct observations to the log.
proc surveyselect data=sashelp.bweight out=work.sample_10_pct_with_replacement seed=1234 samprate=0.1 method=urs; run; proc surveyselect data=sashelp.bweight out=work.sample_5000_obs_with_replacement seed=1234 sampsize=5000 method=urs; run; proc sql; create table work.distinct_rows as select distinct * from work.sample_5000_obs_with_replacement; quit; %put Distinct Observations: &sqlobs.;
Generate Multiple Random Samples
By default, PROC SURVEYSELECT generates one random sample. However, sometimes one sample isn’t enough. So, how do you create multiple random samples in SAS?
You can create multiple random samples in SAS with the REPS=-option. The REPS=-option defines how many random samples the PROC SURVEYSELECT procedure generates. If you use the REPS=-option, then SAS combines all samples into one dataset. You can use the Replicate column to identify each sample.
You can use the REP=-option also when you create stratified samples.
In the example below, we create 3 simple random samples from the BWEIGHT dataset. Each dataset contains 10% of the total number of observations.
proc surveyselect data=sashelp.bweight out=work.sample_10_pct_3_reps seed=1234 samprate=0.1 reps=3; run;
Generate a Systematic Random Sample
The last sampling technique of PROC SURVEYSELECT we discuss is Systematic Random Sampling. With systematic random sampling, you select samples at a preset interval. In other words, if your first sample is the 5 observation and the preset interval is 10, then you will sample the 5th, 10th, 15th, etc. observation.
In SAS, you can create a systematic random sample with PROC SURVEYSELECT and set the METHOD=-option to SYS. The interval at which observations are sampled is based on the SAMPSIZE=-option or SAMPRATE=-option.
In the example below, we create a systematic random sample from the BWEIGHT dataset. To make clearer that SAS samples observations at a specific interval, we first create a new column with the row number of each observation.
data work.bweight; obs_number = _N_; set sashelp.bweight; run; proc surveyselect data=work.bweight out=work.systematic_sample_10_pct seed=1234 samprate=0.1 method=sys; run;
3. Create a Random Sample in SAS with a SAS Data Step
The third method to generate a random sample in SAS is with a SAS DATA Step.
This method consists of three steps and creates a random sample without replacement. This method only works when you want to create a simple random sample with a fixed number of observations.
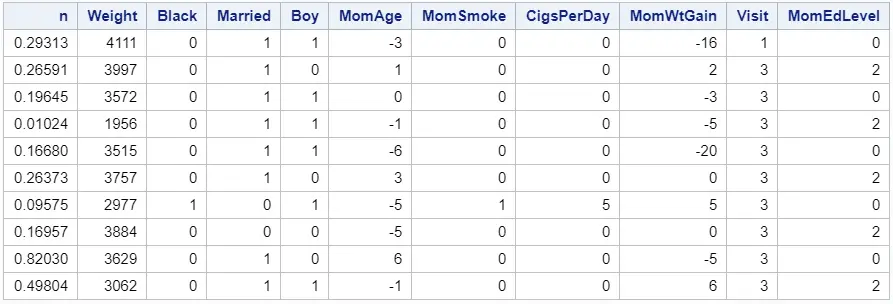
The first step is to add a new column to your dataset with a random number between 0 and 1. You can do this with the RAND function and the Uniform argument. See the example below.
data work.bweight; n = rand("uniform"); set sashelp.bweight; run; proc print data=work.bweight (obs=10) noobs; run;
The second step is to order your dataset (ascendingly) by the values in this new column. You can order a SAS dataset with the PROC SORT procedure.
proc sort data=work.bweight; by n; run; proc print data=work.bweight (obs=10) noobs; run;
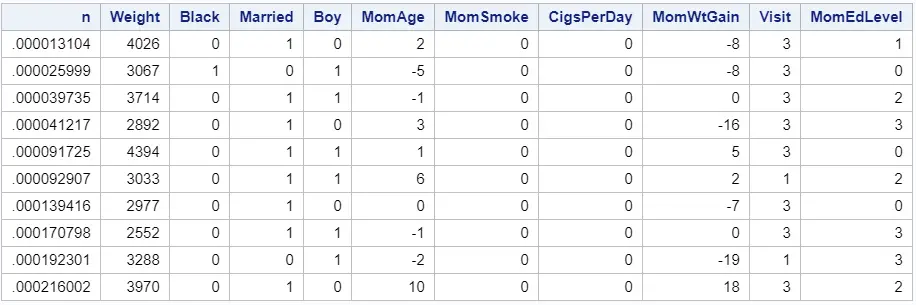
Note that, in the image above, the dataset has been ordered by the variable n.
The last step is to select the first N observations of the ordered dataset. In this case, N is the desired size of the random sample. You can use the OBS=-option to select the first 5000 observations.
data work.sample_5000_obs; set work.bweight (obs=5000); run;
