
In this article, we explain how to rank data in SAS. We use examples and code snippets to demonstrate the most common ways to rank your data. First, let’s create a data set we will rank.
Contents
Ranking Data
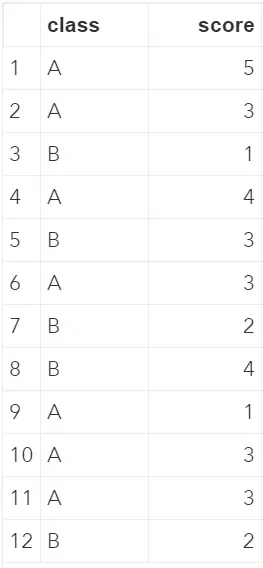
The dataset that will we use throughout this article is shown below. The data contains two columns: class and score. We will use the score variable to rank the data set and the class variable to group our data. The data set contains duplicates on purpose, for example, A 3. We will use these duplicates to demonstrate how to deal with ties in ranking your SAS data.
data work.ds; infile datalines dlm=','; input class $ score; datalines; A, 5 A, 3 B, 1 A, 4 B, 3 A, 3 B, 2 B, 4 A, 1 A, 3 A, 3 B, 2 ; run;
Using _N_
The easiest and most straightforward way to rank your data is by sorting it and creating a new column with row numbers. The code below shows how to order your data set with PROC SORT and how to use _N_ to create a new column with row numbers. This method works fine only if your data isn’t grouped either contains duplicates.
proc sort data=work.ds out=work.ds_srt1; by score; run; data work.rank_n_; set work.ds_srt1; rank = _N_; run;
Using RETAIN
The previous method demonstrated how to rank data without groups nor duplicates. However, it’s fairly common to rank data by groups. We can do this with the RETAIN statement.
First, we order our data set by the group (class) and then by the variable to rank (score). With the BY statement, the FIRST keyword, and a simple IF-THEN statement we assign a value of 1 to our new variable rank if SAS processes a row with a new class. If SAS doesn’t process a row with a new class, then 1 is added to the retained rank, namely the rank of the previous row.
proc sort data=work.ds out=work.ds_srt2; by class score; run; data work.rank_retain; set work.ds_srt2; by class; retain rank; if first.class then rank = 1; else rank = rank +1; run;
Using PROC RANK
In the previous example, we showed how to rank your data by groups. However, we didn’t show how to deal with ties. With the RANK procedure in SAS, you can define how to process ties. You can use PROC RANK also for percentile ranking and ranking multiple variables in one step. First, let’s explain the syntax of PROC RANK.
Besides the obligatory data= and out= statements to define the data set to rank and output (ranked) data set, the PROC RANK procedure has more (obligatory) statements.
- VAR: You use the var statement to specify which variable needs to be used for ranking.
- BY: You use the optional by statement to let SAS know by which group(s) to rank the data.
- RANKS: With the ranks statement you define the name of the new column with the ranks.
proc rank data=work.ds_srt2 out=work.ex_rank_1; var score; by class; ranks rank_score; run;
Ranking with Ties
The methods discussed until now couldn’t deal with ties. With the ties keyword in PROC RANK, you can specify how to work with ties. There are four options:
- MEAN (default): Assigns the mean of the ranks to the new rank variable. So, in the example below, we have four times A 3 with ranks between 2 and 5. The average of 2 and 5 is 3.5.
- LOW: Assigns the minimum of the ranks to the new rank variable.
- HIGH: Assigns the maximum of the ranks to the new rank variable.
- DENSE: Assigns the smallest rank to the new rank variable. The next rank variable is 1 higher than the previous rank.
The image below shows the result of using different values for the ties option.
/* Rank Data - Using PROC RANK (TIES = MEAN) */ proc rank data=work.ds_srt2 out=work.ex_rank_1; var score; by class; ranks rank_score; run; /* Rank Data - Using PROC RANK (TIES = LOW) */ proc rank data=work.ds_srt2 out=work.ex_rank_2 ties=low; var score; by class; ranks rank_score; run; /* Rank Data - Using PROC RANK (TIES = HIGH) */ proc rank data=work.ds_srt2 out=work.ex_rank_3 ties=high; var score; by class; ranks rank_score; run; /* Rank Data - Using PROC RANK (TIES = DENSE) */ proc rank data=work.ds_srt2 out=work.ex_rank_4 ties=dense; var score; by class; ranks rank_score; run; /* Rank Data - All options ties */ data work.rank_ties; merge work.ex_rank_1 (rename=(rank_score=rank_mean)) work.ex_rank_2 (rename=(rank_score=rank_low)) work.ex_rank_3 (rename=(rank_score=rank_high)) work.ex_rank_4 (rename=(rank_score=rank_dense)); by class score; run;
Percentile Ranking
Instead of assigning a rank to an observation based on a specific column, you can also assign the observation to a group. With the groups keyword in the RANK procedure, you can specify how many groups you want SAS to create. In the example below, we create 3 groups per class based on the score.
If you want to separate your data in quartiles you set groups equal to 4, for deciles you need 10 groups, and for percentiles you need to define 100 groups.
proc rank data=work.ds_srt2 out=work.ex_rank_5 groups=3; var score; by class; ranks rank_score; run;
Do you know? 3 Easy Ways to Calculate Percentiles in SAS
Ranking in Descending Order
Until now, SAS gave the lowest rank to the lowest score. However, with the descending option, you can rank your data in descending order. In the example below, we rank the data such that the observation with the lowest score gets the highest rank.
proc rank data=work.ds_srt2 out=work.ex_rank_6 descending; var score; by class; ranks rank_score; run;
Ranking Multiple Variables
In all previous examples, we have created one new column with the rank of the score variable. However, with SAS’ PROC RANK it’s also possible to rank multiple variables at once. For the following example, we have added the column age to our original data set. See the image below.
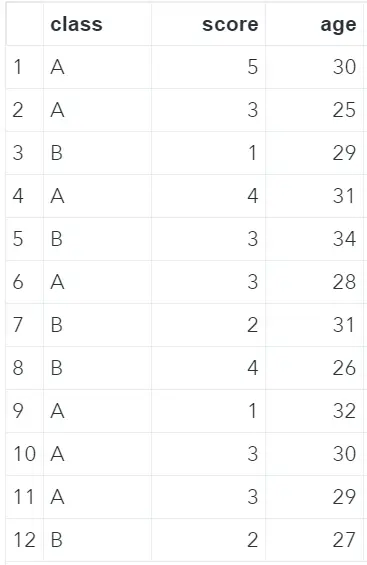
To create an extra column with the rank of the age variable, we need to order our data set first. With the var statement, we specify that we want to create ranks for the variables score and age. Finally, with the ranks statement, we define the names of the new columns with the ranks.
proc sort data=work.ds_2 out=work.ds_2_srt; by class score age; run; proc rank data=work.ds_2_srt out=work.ex_rank_7; var score age; by class; ranks rank_score rank_age; run;
The official SAS documentation of the RANK procedure can be found here.
![5 Best Ways to Concatenate Strings in SAS [Examples]](https://sasexamplecode.com/wp-content/uploads/2020/12/THUMBNAIL_CONCATENATE-400x260.jpg)
3 thoughts on “How to Rank Data in SAS”
Comments are closed.