
A common task while exploring your data is finding the minimum and maximum value of a variable (or column). In a previous article, we showed how to find the minimum value. Here, we’ll discuss how to find the maximum value of a variable in SAS?
You find the maximum value of a variable in SAS with the MAX function in a PROC SQL procedure. The MAX function takes as input the variable of which you want to know the maximum. You can use this method to find the maximum per group, too.
In this article, we show and discuss 5 methods to find the highest value of a column, as well as the highest value per group. The methods that you can use are PROC SQL, PROC MEANS, PROC SUMMARY, PROC UNIVARIATE, and PROC SORT in combination with a SAS DATA Step.
Besides finding the maximum value, we also demonstrate how to select the row with the (second) highest value from a dataset. Again, we do this for the overall maximum value, as well as per group.
Contents
5 Methods to Find the Maximum Value of a Variable in SAS
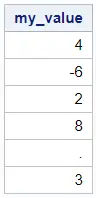
We use a sample dataset to demonstrate the 5 methods that you can use to find the highest value of a variable. This dataset has one column my_value with values between -6 and 8. Notice that there is one missing value.
data work.my_data; input my_value; datalines; 4 -6 2 8 . 3 ; run; proc print data=work.my_data noobs; run;
Do you know? How to Count the Missing Values in a Dataset
Method 1: PROC SQL
The first method to calculate the highest value of a column is with PROC SQL.
PROC SQL is a SAS BASE procedure that you can use to execute SQL code. Hence, if you have experience with SQL this methods will the easiest for you.
The MAX function finds the maximum value of a column in SAS. This function has one argument, namely the column of which you want to find the maximum. It returns the maximum value in this column. The MAX function ignores missing values.
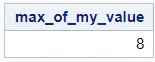
Below we demonstrate how to use the MAX function and find the maximum value of the my_value column.
proc sql; select max(my_value) as max_of_my_value from work.my_data; quit;
If you use the code above, SAS creates only a report. By adding the CREATE TABLE statement to your code, SAS creates an output table instead of a report.
Here we use the CREATE TABLE statement to create the dataset maximum_proc_sql.
proc sql; create table work.maximum_proc_sql as select max(my_value) as max_of_my_value from work.my_data; quit;
Method 2: PROC MEANS
The second method to calculate the maximum value of a variable in SAS is with PROC MEANS.
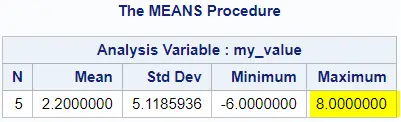
PROC MEANS is a powerful SAS BASE procedure that you can use to analyze columns in your data. By default, it returns the number of observations, the mean value, the standard deviation, the minimum value, and the maximum value. PROC MEANS ignores missing values.
Use the PROC MEANS procedure to find the maximum value of a variable. You use the DATA=-option to define the input dataset. With the VAR statement, you define your variable of interest. PROC MEANS ignores missing values.
Below we demonstrate how to find the maximum value of the my_value variable in the my_data dataset.
proc means data=work.my_data; var my_value; run;
Like PROC SQL, PROC MEANS çgenerates only a report. If you need a dataset with the maximum value of the variable you’re analyzing, you need an OUTPUT statement.
In the OUTPUT statement, you provide the name of the output dataset (OUT option) and the statistic you need. Here we use max=max_of_my_value to let SAS know to create a column called max_of_my_value that contains the maximum value of the my_value column.
proc means data=work.my_data; var my_value; output out=work.maximum_proc_mean max=max_of_my_value; run; proc print data=work.maximum_proc_mean noobs; run;
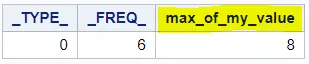
Unfortunately, the output dataset contains two extra columns: _TYPE_ and _FREQ_. You need an extra DATA Step to remove them.
Do you know? How to Remove Columns with the DROP Option
Method 3: PROC SUMMARY
PROC SUMMARY is the third method to find the highest value of a column in SAS.
This procedure is very similar to PROC MEANS. It provides you with the same default statistics. The only difference is that you need to specify explicitly if you want to create a report, an output dataset, or both.
With the SAS code below we create a default PROC SUMMARY report.
proc summary data=work.my_data print; var my_value; run;
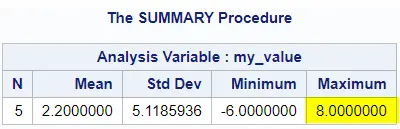
Similar to PROC MEANS, you need to add the OUT=-option to create an output dataset with the results.
Here we use the OUT=-option to create an output dataset called maximum_proc_summary. In this dataset, the column max_of_my_value contains the highest value of the my_value column.
proc summary data=work.my_data print; var my_value; output out=work.maximum_proc_summary max=max_of_my_value; run; proc print data=work.maximum_proc_summary noobs; run;
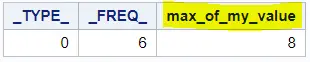
The output dataset contains two unnecessary column. You can use a DATA Step and the KEEP=-option to select only the max_of_my_value variable.
Do you know? How to Select Variables with the KEEP option
Method 4: PROC UNIVARIATE
The fourth method to find the maximum value of a variable in SAS is with PROC UNIVARIATE.
Normally, you use PROC UNIVARIATE to analyze the distribution of a given variable. It even carries out a test for normality. However, you can still use this procedure to calculate the maximum value of a variable.
Because this procedure calculates many statistics and carries out some hypothesis testing, this method can be rather slow compared to the previously discussed methods.
If you run the code below, SAS generates a report. Within the section Extreme Observations, you can find the minimum and maximum values.
proc univariate data=work.my_data ; var my_value; run;
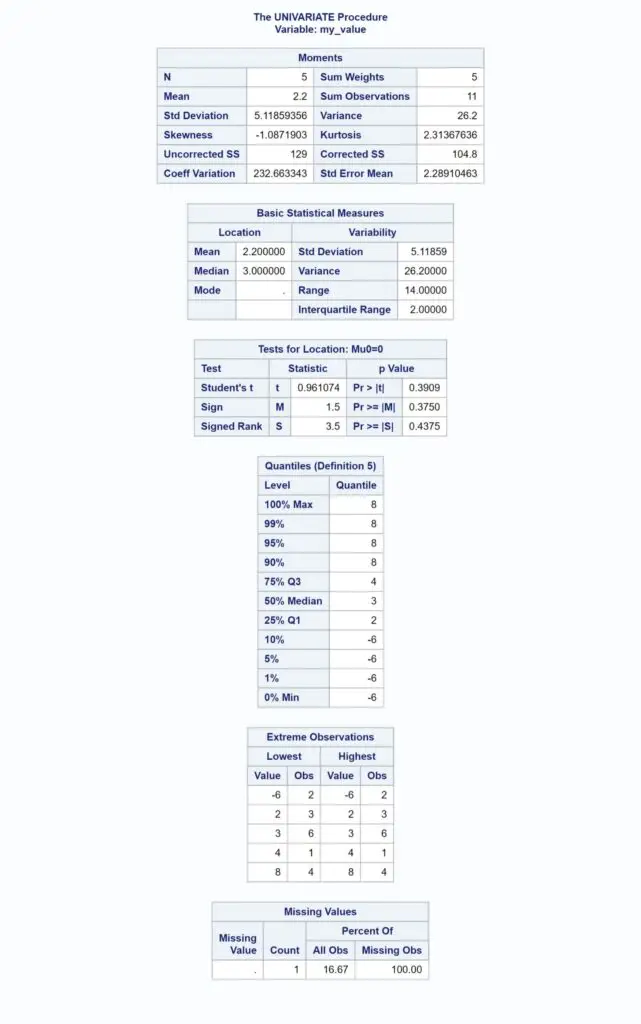
Like the previous procedures, you need to the OUT=-option to create a table with the results. You use the MAX keyword to only add the maximum value of the analyzed column to the output table.
proc univariate data=work.my_data; var my_value; output out=work.maximum_proc_univariate max=max_of_my_value; run; proc print data=work.maximum_proc_univariate noobs; run;
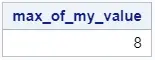
Compared to PROC MEANS and PROC SUMMARY, this method doesn’t create extra columns.
Method 5: PROC SORT + SAS DATA Step
The fifth method to calculate the highest value of a column is a two-step process. You will use PROC SORT and a SAS DATA Step.
The first step is to sort your dataset in descending order with PROC SORT. You use the BY statement, followed by the DESCENDING keyword, and the variable name to sort your dataset. If you order a dataset with missing values in descending order, the missing values are in the last rows in the ordered dataset.
proc sort data=work.my_data out=work.my_data_srt; by descending my_value; run; proc print data=work.my_data_srt noobs; run;
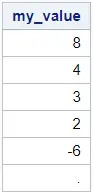
The second step is to select the first row of the descendingly ordered dataset. You can select the first row of a dataset in a SAS DATA Step with the special _N_ variable and an IF-THEN statement.
data work.maximum_data_step; set work.my_data_srt; if _N_ = 1 then output; run; proc print data=work.maximum_data_step noobs; run;
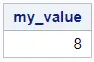
Do you know? How to Select the First 10 Rows of a Table
3 Methods to Find the Maximum Value of a Variable for a Group in SAS
Besides finding the overall maximum value of a column, it’s a common task to analyze the highest value per group. So, how do you find the maximum value of a variable per group in SAS?
For the examples in this section, we use another example dataset. This dataset has 6 rows which are split into two groups, namely A and B. We want to find the maximum for group A and group B. Notice that group B has a missing value.
data work.my_data_groups; input my_group $ my_value; datalines; A 4 A -6 B 2 B 8 B . A 3 ; run; proc print data=work.my_data_groups noobs; run;
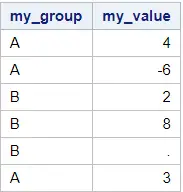
Do you know? How to Create a SAS Dataset Manually
Method 1: PROC SQL
The easiest method to find the maximum value per group in SAS is with PROC SQL.
Use the MAX function and the GROUP BY statement to calculate the maximum value of a group in SAS. With the GROUP BY statement, you define the variable(s) that will define your groups. This variable needs to be present in the SELECT statement, too.
With the SAS code below, we calculate the maximum for each value in the my_group column. If you want to create an output table instead of a report, you need to add the CREATE TABLE statement.
proc sql; select my_group, max(my_value) as max_of_my_value from work.my_data_groups group by my_group; quit; proc sql; create table work.maximum_group_proc_sql as select my_group, max(my_value) as max_of_my_value from work.my_data_groups group by my_group; quit;
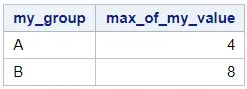
An advantage of this method is that you can easily extend the code to find the highest value of subgroups. You only need to add the extra variables that form the subgroup to the SELECT statement and the GROUP BY statement.
Do you know? How to Calculate the Average per Group
Method 2: PROC MEANS, PROC SUMMARY, PROC UNIVARIATE
A second method to calculate the maximum value per group is with the PROC MEANS, PROC SUMMARY, or PROC UNIVARIATE procedures. If you use one of these procedures, you need two steps.
First, you need to order your dataset by the variable that defines the groups, for example with PROC SORT.
proc sort data=work.my_data_groups out=work.my_data_groups_srt; by my_group; run; proc print data=work.my_data_groups_srt noobs; run;
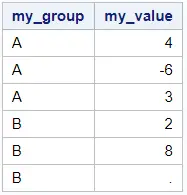
Then, you choose one of the procedures to calculate the maximum per group. With the VAR statement, you define the variable of which you want to know the minimum. To define the groups, you use the BY statement.
/* PROC MEANS */ proc means data=work.my_data_groups_srt; var my_value; by my_group; output out=work.maximum_group_proc_mean max=max_of_my_value; run; /* PROC SUMMARY */ proc summary data=work.my_data_groups_srt print; var my_value; by my_group; output out=work.maximum_group_proc_summary max=max_of_my_value; run; /* PROC UNIVARIATE */ proc univariate data=work.my_data_groups_srt; var my_value; by my_group; output out=work.maximum_group_proc_univariate max=max_of_my_value; run;
We’ve added an OUTPUT statement to each procedure to create an output table with the results. If you omit this statement, SAS creates only a report.
Method 3: PROC SORT + SAS DATA Step
The third method to find the maximum value of a group is with PROC SORT and a SAS DATA Step.
Firstly, you order your dataset ascendingly by the variable the defines the groups in your data and descendingly by the variable of which you want to know the maximum. You can do this with PROC SORT.
proc sort data=work.my_data_groups out=work.my_data_groups_srt; by my_group descending my_value; run; proc print data=work.my_data_groups_srt noobs; run;
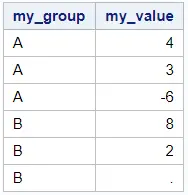
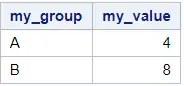
Secondly, you select the first row of each group.
data work.maximum_group_data_step; set work.my_data_groups_srt; by my_group; if first.my_group then output; run; proc print data=work.maximum_group_data_step noobs; run;
Do you know? How to Select the First Row of a Group
How to Select the Row with the Highest Value
Thus far, we have discussed methods to find the highest value of a group. These methods work fine unless you need to select the complete row that has the highest value. That is to say, all columns. So, how do you select the complete row with the highest value?
You can select the row with the maximum value of a given column with PROC SQL and a SAS DATA Step. In PROC SQL, you need to use the HAVING clause. This clause allows you to filter on aggregated functions, such as the MAX function.
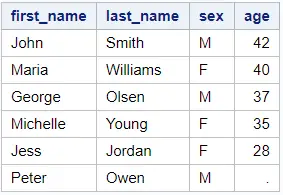
We use a sample dataset to illustrate both methods. This dataset has 6 rows and 4 columns (first_name, last_name, gender, and age). We want to select the row with the highest age. Note that there’s one row with a missing age.
data work.my_data; input first_name $ last_name $ sex $ age; datalines; Maria Williams F 40 John Smith M 42 Jess Jordan F 28 Michelle Young F 35 Peter Owen M . George Olsen M 37 ; run; proc print data=work.my_data noobs; run;
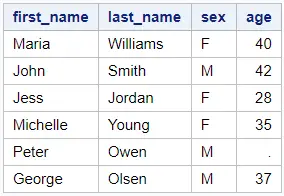
As you can see in the table above, John is the oldest person in our dataset. This is the row we want to select.
How to Select the Row with the Highest Value with PROC SQL
You need 3 steps to select the row with the highest value with PROC SQL in SAS:
- You need the SELECT * (asterisk) statement to select all columns.
- With the FROM statement to specify the input dataset.
- You use the HAVING statement to filter only the row with the highest value.
Although you normally filter data in SQL with the WHERE statement, here you need the HAVING statement. In this case, you filter based on an aggregate function, i.e. the MAX function. Functions such as the MAX function can only be used to filter data in combination with the HAVING statement.
proc sql; select * from work.my_data having age = max(age); quit;
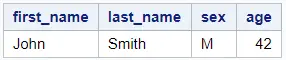
Add a CREATE TABLE statement to the code above to create an output dataset.
How to Select the Row with the Highest Value with a DATA Step
The second method to select the row with the highest value is with PROC SORT and a SAS DATA Step. This is a two-step process. First, you order your data descendingly by the column you want to use to filter your data. Then you use an IF statement and the special _N_ variable to filter the first row.
In the SAS code below, we use PROC SORT to order our dataset descendingly based on the age column.
proc sort data=work.my_data out=work.my_data_srt; by descending age; run; proc print data=work.my_data_srt noobs; run;
The second step is to filter the first row of our ordered dataset. We do this with the IF statement and the _N_ keyword.
data work.select_max_value; set work.my_data_srt; if _N_ = 1 then output; run; proc print data=work.select_max_value noobs; run;
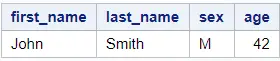
Do you know? How to Select the First Row of a Dataset
How to Select the Row with the Highest Value by Group
A variation to the problem above is how to select the row with the highest value by group? Again, this problem can be easily solved with PROC SQL and a SAS DATA Step.
In the example below, we want to find the oldest person (i.e., highest age) per gender.
How to Select the Row with the Highest Value by Group with PROC SQL
To select the row with the highest value for a specific variable within a group, we need to modify the code mentioned in the previous section slightly. We only need to add the GROUP BY statement. With this statement we specify the variable that defines the groups.
proc sql; select * from work.my_data group by sex having age = max(age); quit;
How to Select the Row with the Highest Value by Group with a DATA Step
To select the row with the highest value for each per gender, we need to order our dataset first by these two variables. We order the dataset ascendingly by gender, and descendingly by age. Then, we use the IF statement and the FIRST keyword to select one row per group.
proc sort data=work.my_data out=work.my_data_srt; by sex descending age; run; proc print data=work.my_data_srt noobs; run; data work.select_max_value; set work.my_data_srt; by sex; if first.sex then output; run; proc print data=work.select_max_value noobs; run;
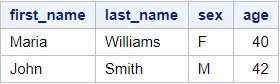
How to Select the Row with the Second Highest Value
The last problem we will discuss in this article is how to select the row with the second highest value?
Although in most cases you want to select the row with the highest value, sometimes it is necessary to get the row with the second-highest value. You can filter this row with PROC RANK and a simple IF statement.
The PROC RANK procedure assigns a rank to each row based on the value of a specified variable (ignoring missing values). With the SAS code below we find the rank for each row based on the age variable. We save the rank of each row in the new variable rank_of_age.
Finally, to select the row with the second-lowest value, we need to filter the row with rank equal to 2. We do this with a simple IF statement.
proc sort data=work.my_data out=work.my_data_srt; by sex; run; proc rank data=work.my_data_srt out=work.ranked_age descending; var age; by sex; ranks rank_of_age; run; data work.select_second_highest_value; set work.ranked_age; if rank_of_age = 2 then output; run; proc print data=work.select_second_lowest_value noobs; run;
Do you know? How to Use PROC RANK


3 thoughts on “How to Find the Maximum Value of a Variable in SAS (5 Easy Ways)”
Comments are closed.