
One of the most common operations in SAS is to filter data. Filters are based on conditions. In this article, we demonstrate, amongst others, how to select the first row (by a group) from a SAS dataset. All examples are supported by SAS code and clear images.
In this article, we use the sample data below. This dataset contains the classification of several competitors in different marathons. We will filter the data set based on the overall race results, as well as on the race results per marathon.
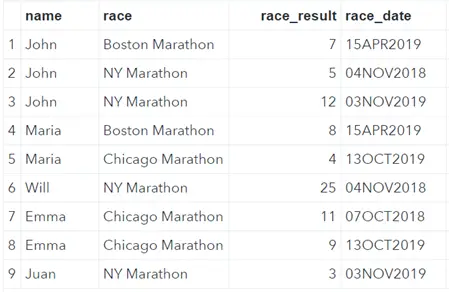
We used the SAS datalines statement in combination with the delimiter option to create this dataset.
data work.my_ds; infile datalines dlm=","; length name race $25. race_result 8; format race_date date9.; input name $ race $ race_result race_date :date9.; datalines; John, Boston Marathon, 7, 15APR2019 John, NY Marathon, 5, 4NOV2018 John, NY Marathon, 12, 3NOV2019 Maria, Boston Marathon, 8, 15APR2019 Maria, Chicago Marathon, 4, 13OCT2019 Will, NY Marathon, 25, 4NOV2018 Emma, Chicago Marathon, 11, 7OCT2018 Emma, Chicago Marathon, 9, 13OCT2019 Juan, NY Marathon, 3, 3NOV2019 ; run;
Contents
Order a SAS Data Set by One Variable
In the next two sections, we demonstrate how to select the first and last row of a dataset. However, the current dataset work.my_ds is not ordered. Since we want to select the best and worst overall classification, i.e., race result, we need to order the dataset first.
We order our dataset based on the race result column in ascending order. Therefore, we use the PROC SORT procedure. We call the ordered dataset work.my_ds_srt.
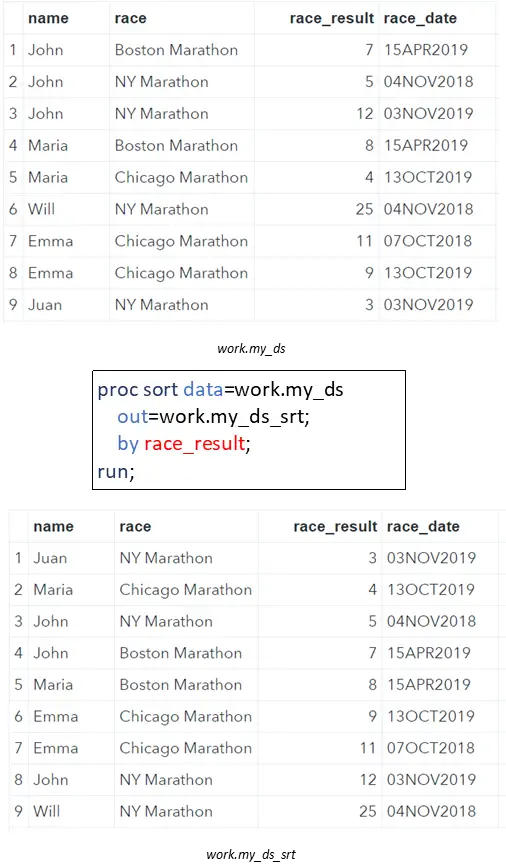
proc sort data=work.my_ds out=work.my_ds_srt; by race_result; run;
Select the First Row of a Data Set
Now that our data set is ordered in ascending order, we can easily select the first row to obtain the athlete with the best overall race result. We use the OBS=-option in the SET Statement to filter the first row.
With this option, you can specify the last row that SAS processes from the input dataset (work.my_ds_srt). Since we are only interested in the first row, we use OBS=1. That is to say, we process the first row and stop directly afterward.
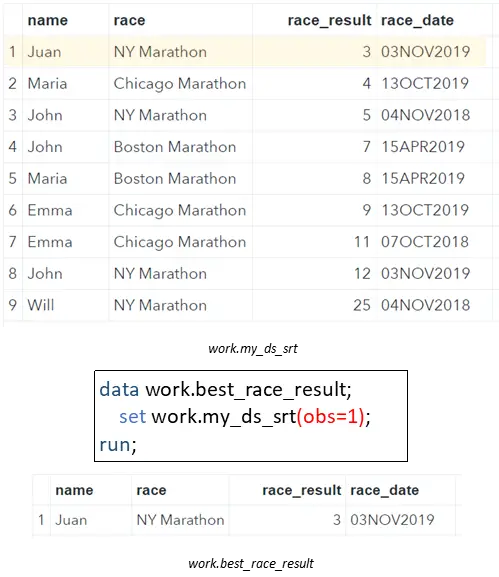
data work.best_race_result; set work.my_ds_srt(obs=1); run;
Select the Last Row of a Data Set
Like filtering the first row of a dataset, it is also very easy to select the last row of a dataset. Instead of the OBS=-options, we use the END=-option.
With the END=-option, you can create a boolean variable that is TRUE if SAS is processing the last row of the input dataset and FALSE otherwise. So, if you combine the END=-option with an IF-statement, it’s easy to select the last observation of a dataset. The IF Statement is only true when we process the last row of work.my_ds_srt, and hence, will only copy this row to the output dataset.
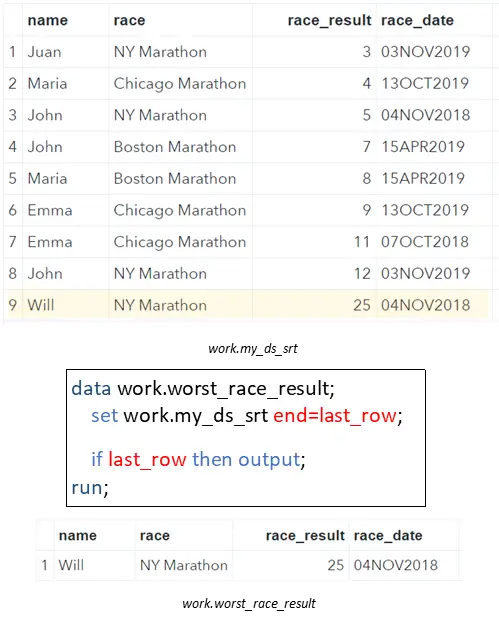
data work.worst_race_result; set work.my_ds_srt end=last_row; if last_row then output; run;
Order a Data Set by Multiple Variables
So far, we have shown how to select the first and last row of a dataset. However, sometimes it is necessary to select the first (or last) row from a specific group in your SAS dataset. Before we can do this, we need to create groups first.
In SAS, you can create groups within a dataset with the PROC SORT procedure. In our examples, we want to group our data by race and order each group by race_result in ascending order. To do so, we need both the race variable and the race_result variable in the BY Statement of the PROC SORT procedure.
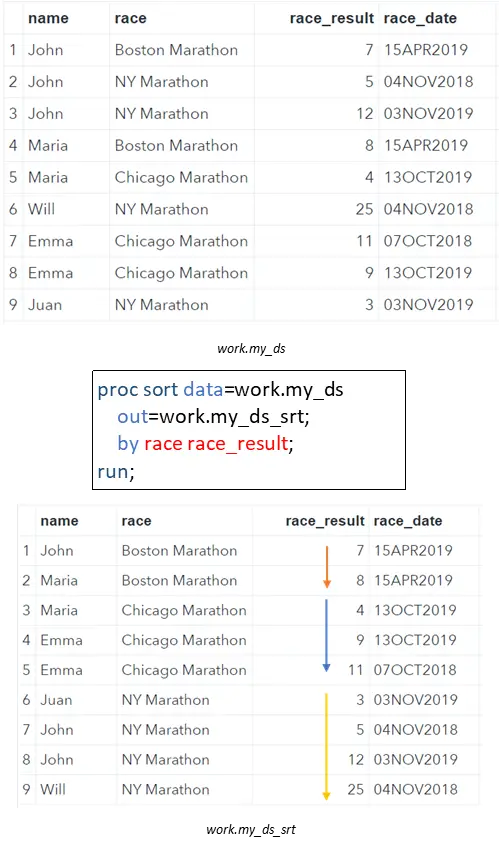
proc sort data=work.my_ds out=work.my_ds_srt; by race race_result; run;
Select the First Row by Group
Now that our dataset is ordered by race and race_result, we can select the first row from each group, i.e., the athlete with the best classification per marathon.
We select the first row of a group in SAS with the FIRST-variable. This special variable takes the values 0 and 1. When SAS is processing the first row of a group, the FIRST.variable takes the value 1. In all other cases, the FIRST.variable is 0. You define the groups with the BY statement.
In our example, the FIRST.race variable is 1 when SAS processes row 1, 3, and 6 because these are the first row of each “race-group”. Because the number 1 has the same meaning as TRUE, we can use FIRST.race in an IF Statement to filter the first row per group.
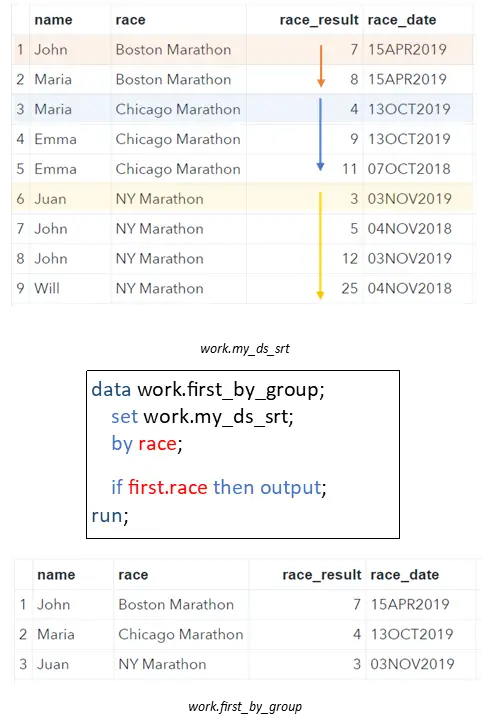
data work.first_by_group; set work.my_ds_srt; by race; if first.race then output; run;
If you want to select the first row of a group, but instead SAS returns the error ERROR: BY variables are not properly sorted on data set, then you need to check two things:
- Did you order the input dataset correctly with the PROC SORT procedure?
- Did you define the groups correctly with the BY Statement in the SAS Data Step?
Select the Last Row by Group
Like the FIRST.variable, there also exists the LAST.variable. As you might expect, you can use the LAST.variable to select the last row of a group in SAS. The LAST.variable takes the value 1 if SAS processes the last row of a group, and 0 otherwise. You use the BY statement in the SAS Data Step to define the group(s). Because we are interested in the worst race result per race, we can use the LAST.race in combination with an IF Statement.
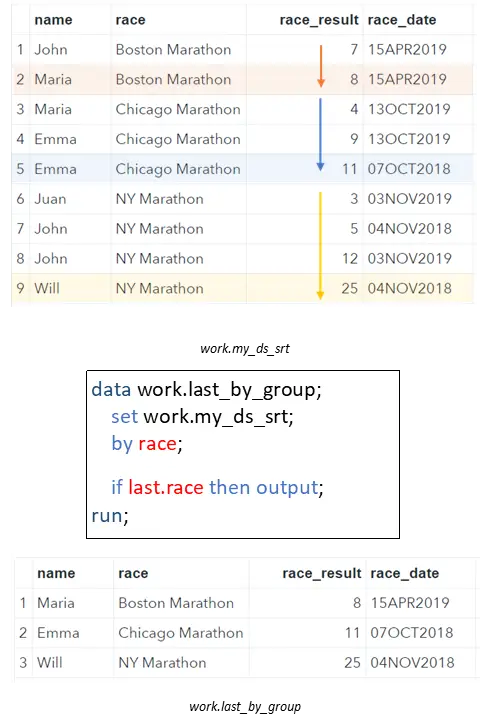
data work.last_by_group; set work.my_ds_srt; by race; if last.race then output; run;
Note that, instead of using the LAST.variable, you can also modify the PROC SORT procedure and use the FIRST.variable to select the worst classification per race.
Select the First Row by Group with SQL
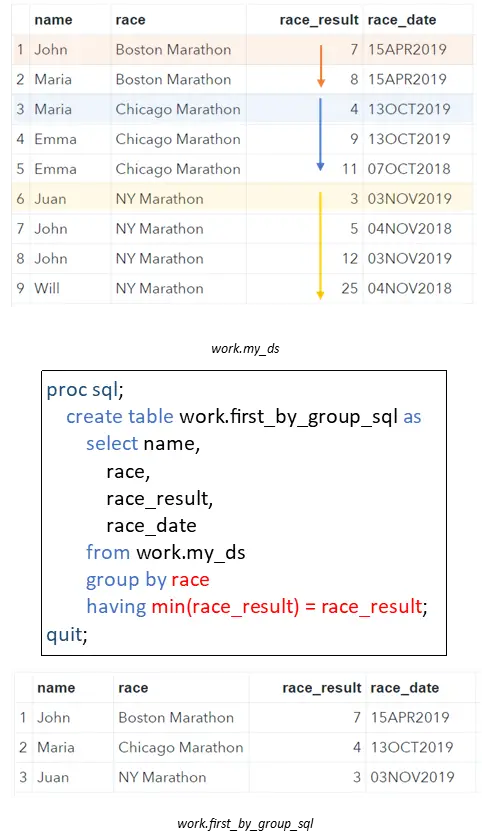
Instead of using a SAS Data Step to select the first row from a group, you can also use SQL code. In the PROC SQL procedure, we use the GROUP BY statement to define a group. With the HAVING statement, we filter only those rows from a group that meet a condition.
In our example, we use GROUP BY race to group our table based on the race column. With the HAVING min(race_result) = race_result, we select the observation with the best (lowest) race result in a group.
You can use the same SQL code to select the last observation per group. You only need to change min(race_result) into max(race_result).
An advantage of this method to select the first/last row of a group is that it isn’t necessary to order the original data first. The PROC SQL procedure does this automatically.
proc sql; create table work.first_by_group_sql as select name, race, race_result, race_date from work.my_ds group by race having min(race_result) eq race_result; quit;
Select the First N Rows by Group with Retain
So far, we have discussed how to select the first and last row (of a group) from a SAS dataset. However, in some circumstances, it might be necessary to filter the first N rows per group. In this section and the next one, we demonstrate how to do this with two different methods.
The first method to select the first N rows per group from a SAS data set is using the RETAIN keyword in combination with the FIRST.variable. To fully understand how this method works, let me briefly elaborate on the RETAIN keyword first.
SAS processes a dataset row by row. Each time SAS goes to the next row, it “forgets” the previous row. However, with the RETAIN statement you can let SAS know to “remember” as certain value from the previous row.
In the example below, we create a variable n that stores the row number of the observation in its specific group. When we switch to the next row, SAS will “remember” the value of n because we used the RETAIN statement.
With the FIRST.variable we can set the n variable to 1 if we reach the first row of a new group. If FIRST.variable equals 0, i.e., not the first row of a group, then we add 1 to the current value of the n variable. With the output statements, we copy all rows to the output dataset (work.first_2_by_group) that are the first row of a group or if n <= 2.
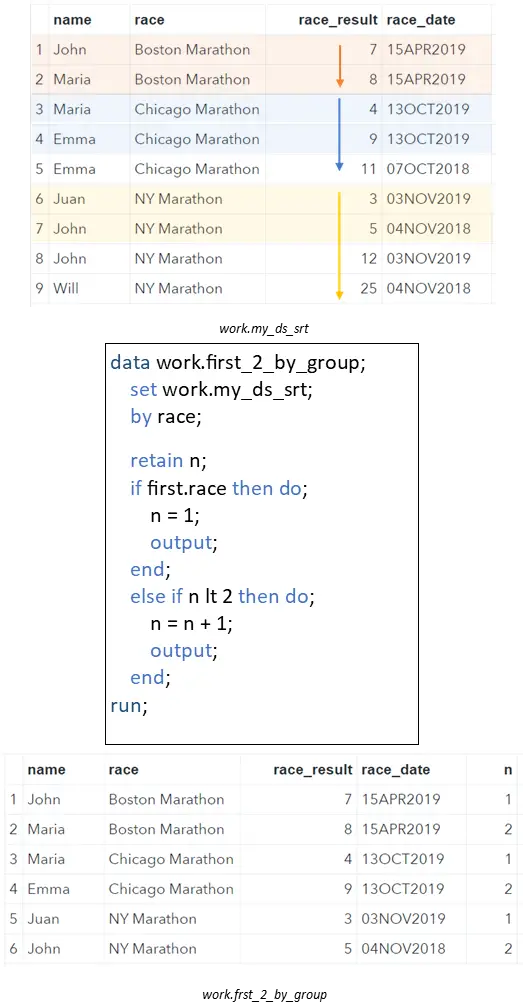
data work.first_2_by_group; set work.my_ds_srt; by race; retain n; if first.race then do; n = 1; output; end; else if n lt 2 then do; n = n + 1; output; end; run;
Select the First N Rows by Group with PROC RANK
Another method to select the first N rows from a group is with the help of the PROC RANK procedure. With this procedure you can determine the rank, i.e., position of each observation within a group.
In the example below, we use the BY statement in the PROC RANK procedure to define our groups. Then, with the VAR statement we let SAS know by which variable to order each group. With the RANKS statement you can define the name of the column that stores the rank of each observation. Finally, we use this new group_rank variable in combination with an IF statement to select the first 2 rows per group.
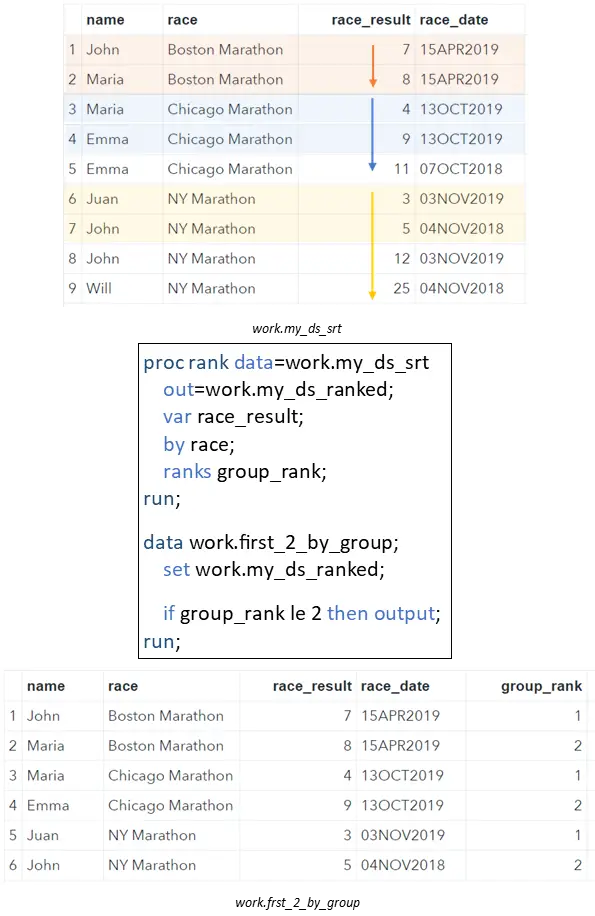
proc rank data=work.my_ds_srt out=work.my_ds_ranked; var race_result; by race; ranks group_rank; run; data work.first_2_by_group; set work.my_ds_ranked; if group_rank le 2 then output; run;
If you are interested in our ways to select certain observations from a dataset, please read this article.
